| Version 7 (modified by meddle, 15 years ago) (diff) |
|---|
Analysis
Overview
The Server have to keep it's resource data in a flexible and extend-able database. The information should be stored and loaded when the Server is restarted, the current functionality should continue to work.
Task requirements
- Choose an appropriate database for storing.
- Create a good database schema for storing the resources and the history
- Store in the database the resources and the history
- Should be able to pick a resource data at a specified revision
- Should be able delete and create a resource in the database
- Should be able to store the changes of an resource in the database.
- Create an API that communicates with the database using JDBC.
- Create a JDBC template to query easy the DB
- Think of a way to manage the DB connection
- Connecting to the DB should be treadsafe.
- Make the facade and the web use the database
- Preserve the current functionality - collaboration, skipping changes, web upload/download/browse/delete
- Make a mock server from the old implementation of accessing resources in the server memory (optional)
Task result
Source code and tests.
Implementation idea
- Use H2 database for the database.
- Use ThreadLocal connection variables for the ThreadSafe connections.
- Create special WebResourceAccess to replace the current mem accesses in the web, but to preserve working with helpers.
- Use the current Persistence API to store the immutables in the DB.
Related
No related tickets for now...
How to demo
- Show the working web and collaboration in Sophie but with the DB implementation
- Web interface
- Upload a book through the web interface
- Browse the books in the web interface
- Download and delete the book.
- Collaboration
- Save a book on the server
- Make some changes from different Sophie clients
- Undo the change, redo them
- See the actions in all the clients
- Web interface
Design
Database and JDBC template
Database and schema
- The choosen database is H2 DB -> Homepage
- The other canditates were:
- Derby or JavaDB, it is Sun's embedded database used mainly for Java Application, but in comparison to the H2 there are no inner optimizations with the transactions and there are some problems
- Hypersonic -> The embedded DB of Hibernate, it is simmilar ot H2, but its main purpose is to be used with Hibernate.
- The H2 database has a JDBC implementation and comes with one jar, added as dependency to the server.core module.
- It can be embedded in the memory (The virtual machine), in file or to be used as server and client
- In Sophie 2 it will be used as Embedded in the memory (JVM) and stored into a file.
- JDBC can access the DB with similar URLS "jdbc:h2:path_on_the_machine;AUTO_SERVER=TRUE", the AUTO_SERVER_TRUE here means that if another client tries to connect to the DB our clent will continue to be connected, and not rejected, also means that if another client is connected already to the DB, our client will not be rejected...
- The other canditates were:
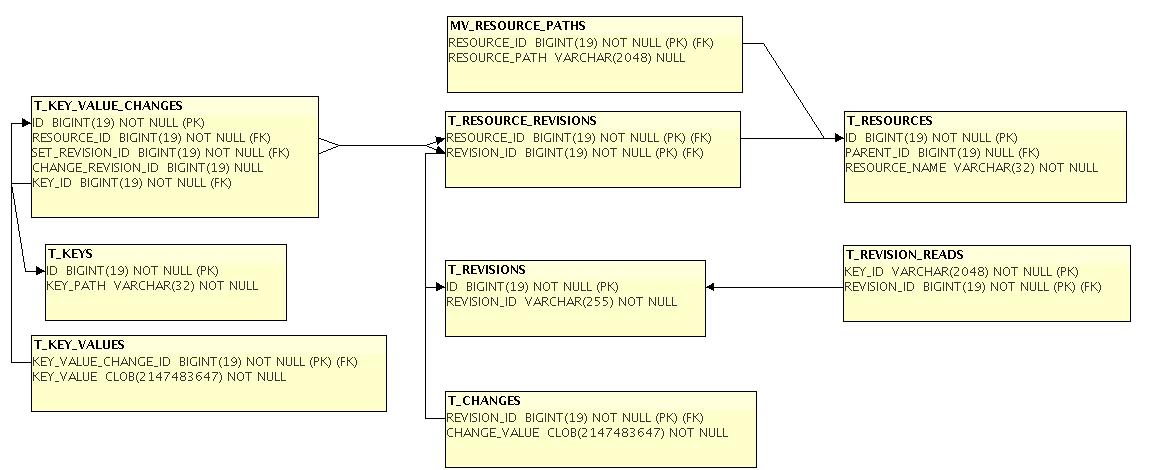
- Schema -> The schema will be constructed in sucha way that the queries to the DB could be optimal (It will be normalized and if you want for example to see the value of a given key of a given resource at a given revision, you will not need to select the change caused the revision, ie every logiical kind of data will be iiiin separate table)
- Tables that have unique data will be named in the following convention : T_TABLENAME (T comes from table)
- Tables that can be viewed with a series of joins on the other tables and are used mainly for ease when selecting will be names MV_TABLENAME (The V is from view, the M comes from multiple (tables))
- TODO SCHEMA_AND_DESCRIPTION_HERE
JDBC Template
- For our purposes using JDBC is enough there is no need of ORM like Hibernate and bean model for it, because we will have small database.
- The queries for selecting/updating/inserting data can be categorized and there will be one class that gives methods for using them. This class will capsulate all the actions using JDBC and will take care with the JDBC API for the developers.
- The base API is plased in the org.sophie2.server.core.persistence.db.jdbc package of the server core module, some of the implementations of the interfaces that are used for specific actions with resources are in the org.sophie2.server.core.persistence.db package, where is the Server Resource Persistence API, i.e. specific classes for managing resources.
- Class : JdbcTemplate -> Responsible for releasing all the JDBC resources that are used for query like ResultSets and Statements. It is not responsible for managing JDBC Connections.
- The JdbcTemplate class can be constructed with a ConenctionManager (used for retrieving of threadsafe connections to the DB and commit and rollback of transactions)
- Public methods:
- public <T> T execute(SQLCallback<T> callback) -> Used for executing SQLCallbacks (Actions that executeeeeee sql queries) to the database. It returns the result of the callback. If there is any error, the current transaction to the DB will be rollbacked and the connection closed (This method must be use by all methods executing queries, it takes care of errors in the JDBC or in the DB)
- public <T> T execute(final ConnectionCallback<T> action) throws JdbcException -> Used to execute a ConnectionCallback (Actions which use JDBC connections). This execute method uses the mentioned above one, creating a SQLCallback that executes the ConnectionCallback in a connection retrieved by the ConnectionManager. (This method takes care of retrieving the connections, it should release the connection if there is no user made transaction and there no errors)
- public <T> List<T> queryForList(String sql, RowMapper<T> rowMapper, Object... parameters) -> Method for executing queries to the database which return list data, for example for selecting a list of resource names...
- public <T> T queryForObject(String sql, RowMapper<T> rowMapper, Object... parameters) -> Used for executing queries that hase a single result, for example the name of a resource with a given database ID.
- public <T> T query(final String sql, final ResultSetMapper<T> mapper, final Object... parameters) -> Executes a query with a list of parameters, used by the two methods above.
- public <T, P> T query(final String sql, final ResultSetMapper<T> mapper, final ParametersSetter<P> parametersSetter) -> The same as the above one, but its query parameters are managed by a given ParameterSetter.
- public int update(final String sql, final Object... parameters) Used for a single update to the databse, it returns the update count of the query.
- public int[] updateBatch(final String sql, final Collection<Object[]> parameters) Executes a number of updates to the database with one query string, but with different parameters, used by the above method for one update.
- public int[] updateBatch(final String sql, final ParametersSetter<Object[]> parametersSetter) The same as the above, but using ParameterSetter to manage the parameters and used by the above.
- public int[] updateBatch(final String sql, final ParametersSetter<Object[]> parametersSetter) Executes an insert to the database, there are analogical insertBatch method as the update ones.
- public ConnectionManager getConnectionManager() -> Getter of the ConnectionManager of the template.
- commit() and rollback() methods for user made transactions that can be commited or rollbacked by the user, the use the ConnectionManager.
- As you can see there are plenty of public methods some of which should be protected or private (the batch methods, the query and execute methods), They are public because the user may not be able to change the template but wants to write qa query different from just insert/update one query or selllect one object or one list of objects, if you have oppinion on which of these methods should be private/protected, please write it in the review.
- Interface : SQLCallback<T> -> Represents a callback to the database using sql query.
- Public methods:
- public T doSQL() throws SQLException -> Executes a SQL query using the JDBC API, which can throw SQLException...
- Its implementations are used to manage the connection from the connection manager and use a ConnectionCallback.
- Public methods:
- Interface : ConnectionCallback<T> -> Represents a callback to the database with managed JDBC connection.
- Public methods:
- public T doInConnection(Connection conn) throws SQLException -> Executes a SQL query using the provided connection.
- The SQLCallbacks retrieve and manage connections, and their doSQL method instantiates ConnectionCallbacks that use that connections. The execute methods of the JDBCTemplate deal with the SQLExceptions and if it is needed throw our JdbcException.
- Public methods:
- class : JDBCException -> The exception thrown when something is wrong with the JDBCTemplate queries. It is unchecked and in general represents unchecked SQLException.
- class : ConnectionManager -> Manages the connections to the database, provides thread safe connections and provides methods for strating transactions and rollback of transactions.
- The manager is constructed by a DataSource (From the JDBC API, the data source can provide a connections from a pool, for reusing...)
- Public methods:
- public Connection getCurrentConnection() -> Retrieves the current connection, if there is no such connection, gets one form the DataSource.
- public void releaseCurrentConnection() throws SQLException -> Releases the current connection if it is not used by a transaction.
- public void commitCurrentTransation() throws SQLException -> Commits the current transaction.
- public void rollbackCurrentTransation() throws SQLException -> Rollbacks the current tansaction.
- public DataSource getDataSource() -> Getter of the data source of the manager.
- Interface : RowMapper<T> -> Used to map a row of data selected from the database to an object or list of objects.
- Public methods:
- public T mapRow(int rowNum, ResultSet rs) throws SQLException -> Maps a specified row of the passed ResultSet (JDBC API) to an object or list of objects.
- Implementations:
- LongRowMapper -> Maps the first cell in a row to a Long value.
- StringRowMapper -> Maps the first cell to a String value.
- Public methods:
- Interface : ResultSetMapper<T> -> Maps a ResultSet (JDBC API, contains a result from query) to an Object or list of objects, its implementations often use RowMappers to iterate over the ResultSets.
- Public methods:
- public void mapRow(int rowNum, ResultSet resSet) throws SQLException -> Maps a row from the ResultSet to a value.
- public T getResult() -> Getter for the result of the mapping. Ususally the implementator will iterate through a ResultSet and for each of its rows will call mapRow ot the mapper, then after all the rows are iterated will retrieve the result with this method. OFten the implementations use RowMappers to map the columns of a given row.
- Implementations:
- KeyMapper -> Maps a result to pair keypath and its id in the database.
- ListMapper<T> -> Maps a result to a list of objects, uses RowMapper to map the separate rows.
- SingleResultMapper<T> -> Maps a result to a single object, used with select queries that return only one row.
- Public methods:
- Interface : ParameterSetter<T> -> Manages setting the parameters to a PreparedStatement (JDBC API)
- Public methods:
- public void setParameters(int batchIndex, PreparedStatement stmnt) throws SQLException -> Sets parameters to a specified statement, it can set different parameters to one statement and its first parameter means which batch of parameters will be set.
- public int getBatchesCount() -> The number of the batches of the parameters of the setter.
- Implementations:
- DefaultParameterSetter -> Manages setting the parameters to a given statement. It is constructed with its parameters, represented as an array of objects for every batch. All the batches are contained in a Collection.
- Public methods:
The API Used by the Facade and the Web Interface
ResourceDAO
- DAOs (comes from Data Access Objects) are something like services that has simple methods for managing a database. They do contain only logic that keeps the data in database valid and logic for selecting of specified data.
- Our DAOs are ment to use the JDBCTemplate and the ConnectionManager to manage the database.
- There is only one DAO for now - ResourceDAO, in future there cаn be more, SecurityDAO for example...
- Class : ResourceDAO -> Gives simple methods to persist/retrieve and edit resources, their keys and revisions (history).
- Keeps inner constants with the names of the queries stored in the queries.properties file in the server.core module.
- Uses the SqlQueries util to load the queries from the properties file.
- Can be constructed only with an instance of JDBCTemplate. So to use the DAO a developer needs to retrieve a JDBC DataSource to a database, construct from it JDBCTemplate and use the template to instantiate the DAO.
- Public methods:
- public JdbcTemplate getJdbcTemplate() -> Getter of the JDBCTemplate in the DAO.
- public Long findResourceIdByPath(String resourcePath) -> Finds the DB id of an resource by it's path on the server, for example "/resources/My Book.book.s2" is such path. With that id the resource can be edited, or viewed freely.
- public Long createResource(final Long revisionId, DBResource resource) -> Creates a resource in the database and flags it like 'alive'. Returns the DB id of the new resource. the DBResource POJO keeps the data of the new resource to be inserted.
- public Long createRevision(DBRevision revision) -> Creates a revision in the database, needed to be done before creating a resource for example,
- public Long findOrCreateKey(String keyPath) -> Retrieves the db id of a key, if the key does not exists creates a record for it in hte DB. Proper key paths are for example 'kind' or 'title'...
- public void changeKeys(final Long revisionId, final Set<DBKeyChange> changes) -> Changes specified key values in the DB, and for that change new revision for the resource owning the keys is created. The revisions are global for now, so every revision changes the main resources directory. Only the sub resources that have changed keys are taken in mind retrieving the changes for the revision though...
- public void readKeys(Long revisionId, List<Key<?>> reads) -> Registers reads for specified keys at a given revision.
- public void readKeys(Long revisionId, List<Key<?>> reads) and public Map<Key<?>, Long> getRevisionCausingWrites(String resourcePath, String revisionId) -> Used to retrieve the changed and readed keys causing a specified revision. Used for the skip algorithm.
- public Map<Key<?>, Long> getRevisionModel(String resourcePath, String revisionId) -> Gets a model skeleton for a given revision of a given resource, this skeleton is usefull for building a lazy DB ResourceModel. public String getValueForKey(Long valueId) is used with the value ids in the result map corresponding to keys.
- public String findRevisionNotAfter(String revisionId) -> Finds the revision id of the revision which is the passed one, or if the passed one does not exist, the last existing one before it. Can be used with the FUTURE revision id to find the current revision on the server.
- public String findValue(String resourcePath, String keyPath, String revisionId) -> Finds a value of a key of specified resource at specified revision.
- public String getPreviousRevision(String revId, String prefix) -> Retrieves the previous revision of a resource with specified revision.
- public SortedMap<String, String> findHistory(String resourcePath, String from, String to, Integer offset, Integer limit) -> Retrieves a history for a resource (specified by its path) in the form of map containing revision ids as keys and the causing changes of the revisions for that ids (persisted to strings) as values.
- public List<String> findChildResources(String resourcePath) -> Retrieves the value of the ChildrenKey.
- public List<String> findResourceKeys(String resourcePath) Finds the names of all the modified keys for a resource.
- All these methods are created because of the needs of the resource model logic, like retrieving history, model at revision, skiping, changing and reading keys...
- Objects used to contain data for the ResourceDAO
- DBKeyChange -> Contains a value for a key of a given resource, constructed by the DB ids of the key and the resource and the value as a IO Reader. The JDBC API persists streams...
- DBResource -> contains a name ofor a new resource and its parent resource DB id.
- DBRevision -> contains a revision id for a new revision and it's causing change stored to a IO Reader.
Resource Helpers
- The old logic will be kept as a mock server in the memory only.
- For that to happen ServerResourceHelpers will be registered as extensions. These helpers will be used to retrieve ResourceServices for the facade, to open accesses to resources and to initialize server module environment.
- May be in the s2s ServerModule there will be extension point for them. Ideas form the reviewers here? And you can give better names for the classes too.
- Interface : ServerResourceHelper -> Initializes Server model environment (like DB or connection to DB, ResourceLocator or some other thing)
- Methods:
- void initialize() -> Initializes the environment, for example creates a ResourceLocator -> AppLocator or creates connection to a DB.
- ResourceService getResourceService(String serverUrl) -> Retrieves ResourceServices for example the old mem access implementation is moved in such service, the ServerFacade works with services and they generate its Response to the client.
- ResourceAccess getResourceAccess(ResourceRefR4 ref, String serverLocation) -> Retrieves (opens) ResourceAccess to a resource specified by its ref. Accesses for books on the server can be retrieved by this way for example.
- Methods:
- Implementations - For now two, the old mem access implementation and the new DB implementation:
- ServerResourceHelperAccessImpl -> Creates a memory resource dir when initialized and opens memory accesses to resources in it. The ResourceService provided by it works with memory resources.
- ServerResourceHelperDBImpl -> When initialized it connects to the database in the dist directory of the core module, if the schema does not exist, it creates it using the schema.sql file and puts a resource dirctory in it (the main directory), creates services using a dao created by JDBCTemplate conected to the DB and opens DBResourceAccesses to the database.
Resource Services
- The services manage the resource model.
- They are used by the ServerFacade and contain some of the Response logic, like the ResponseExceptions, if there is some problem on the server.
- The services are something like a server alternative of the ResourceAccesses, there is a special DBResourceAccess that uses service to adapt the logic of the accesses on the server. However the facade needs the Response logic of the services and works with them.
- Interface : ResourceService -> Can be retrieved form the Resource Helpers and constructed/cached by them.
- Methods:
- <T> T findValue(ResourceRefR4 ref, Key<T> key, RevisionId revisionId) throws ResponseException -> Finds value of a key for resource specified by the passed ref at the specified revision. If there is problem finding the value throws a ResponseException for the ServerFacade. Can retrieve any value at any revision of the resource.
- <T> T findValue(ResourceRefR4 ref, Key<T> key) throws ResponseException -> The same as the above but for the current revision. This method is the server alternative of ResourceAccess.getRaw(Key<T>)..
- Methods:
Implementation
(Describe and link the implementation results here (from the wiki or the repository).)
Testing
(Place the testing results here.)
Comments
(Write comments for this or later revisions here.)
Attachments
-
DB Graph.jpg
(77.4 KB) -
added by mira 15 years ago.
DB Schema
{kind=link}
{kind=link}